Lors du développement d’une application pour un site e-commerce, j’ai récemment rencontré un problème épineux : comment gérer la pagination des produits tout en respectant les principes du Domain-Driven Design (DDD), de l’Architecture Hexagonale et du Command Query Responsibility Segregation (CQRS) ? Je me suis longtemps demandé si la pagination devait faire partie du Domaine, et si non, comment faire le lien entre la couche Infrastructure, ou la couche Application, et le Repository qui se trouve dans la couche Domaine. Comment alors respecter les règles des architectures qu’on a choisi d’utiliser ? Je vous livre dans cet article mon cheminement et mes analyses.
Rappel des différentes méthodologies de développement utilisées
Domain-Driven Design
Le DDD est une approche de développement logiciel qui place le Domaine métier au cœur du développement. Pour cela, on utilise plusieurs patterns logiciels, comme par exemple les Entity, les Aggregate, les Value Object, les Repository… Cependant, utiliser seulement les patterns techniques est une mauvaise utilisation du DDD. En effet, l’essentiel réside dans l’utilisation de l’Ubiquitous Language et dans la modélisation du Domaine. Le DDD encourage une collaboration étroite entre les développeurs et les experts métier pour créer un modèle commun. De plus, le concept de Bounded Context est essentiel pour délimiter les sous-domaines et gérer la complexité du système.
Architecture Hexagonale
L’Architecture Hexagonale (aussi connue sous le nom d’architecture Port/Adapter) prône la séparation d’une application en plusieurs couches et vise à rendre le Domaine indépendant de l’extérieur (base de données, framework…). Deux couches sont obligatoires : le Domaine, avec le code métier (les Entity, les Aggregate, les Value Object, les Repository…), et l’Infrastructure, qui gère les communications avec l’extérieur grâce aux Adapters d’entrées (les Controllers) et aux Adapters de sorties (les Repository).
Les deux couches communiquent en utilisant l’inversion de dépendance. On définit une interface dans le Domaine (par exemple un Repository, avec la méthode Add) et l’Infrastructure fournit l’implémentation de la méthode Add du Repository pour enregistrer la nouvelle Entity en base de données.
Command Query Responsibility Segregation (CQRS)
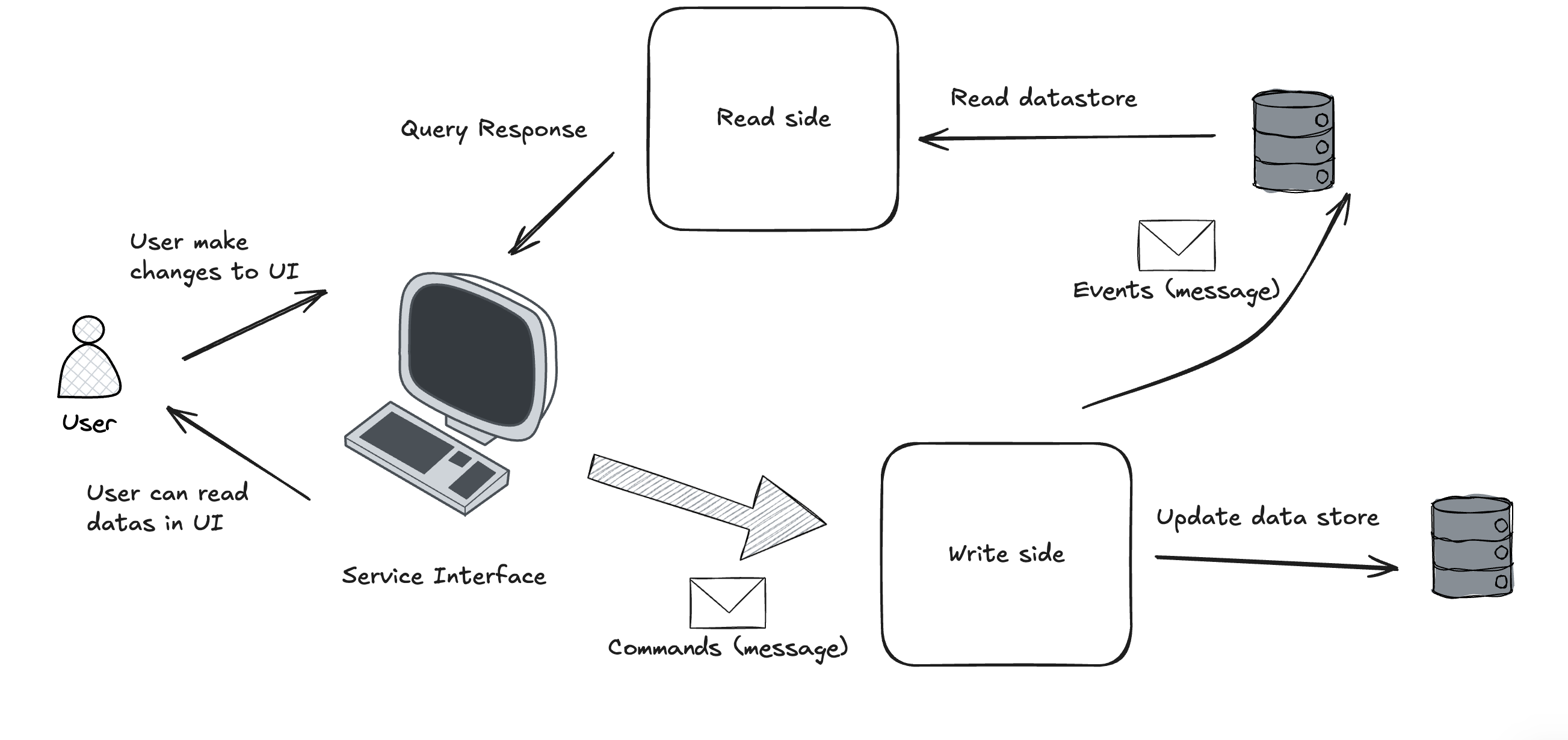
Le CQRS est un pattern qui stipule que toute action sur le système est soit une Query (pour lire dans le système) soit une Command (pour effectuer une action et modifier le système). Une Command ne retourne rien ou l’identifiant de la ressource créée. Le CQRS impose aussi de séparer le modèle d’écriture et le modèle de lecture.
Cas pratique : liste de produits paginée pour un site de e-commerce
Pour cet article, je vais prendre comme exemple un cas classique pour les sites de e-commerce : une liste de produits paginée sur laquelle on peut faire une recherche par nom de produits. J’exposerai ensuite pourquoi la solution peut sembler simple mais qu’elle soulève une question.
Mise en œuvre initiale
Pour commencer, j’ai créé une Entity Produit dans le Domaine :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
namespace App\Domain\Entity;
final class Product
{
public function __construct(
private ProductId $id,
private ProductName $name,
private ProductPrice $price,
) {}
public function id(): ProductId
{
return $this->id;
}
public function name(): ProductName
{
return $this->name;
}
public function price(): ProductPrice
{
return $this->price;
}
}
L’id, le name et le price sont tous les trois des Value Object.
L’interface du Repository fait aussi partie du Domaine :
1
2
3
4
5
6
7
8
9
10
11
12
namespace App\Domain\Repository;
use App\Domain\Entity\Product;
use App\Domain\ValueObject\ProductName;
interface ProductRepository
{
/**
* @return Product[]
*/
public function getProductsWithName(ProductName $name, int $itemPerPage, int $page): array;
}
Je ne parlerai pas de l’implémentation de cette interface dans cet article, car cela n’a aucun intérêt pour traiter le sujet du jour.
La Query et le QueryHandler, qui sont en charge de formater et de faire le lien entre le Domaine et l’extérieur, peuvent se trouver soit dans la couche Infrastructure, soit dans la couche Application. Pour éviter de rajouter une couche dans cet exemple, je les ai mis dans la couche Infrastructure, même si personnellement je préfère les mettre dans la couche Application.
Voici la Query :
1
2
3
4
5
6
7
8
9
10
11
namespace App\Infrastructure\Query;
final readonly class ListProductsWithNameQuery
{
public function __construct(
public string $name,
public int $itemPerPage,
public int $page,
) {
}
}
Et le QueryHandler :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
namespace App\Infrastructure\Query;
final readonly class ListProductsWithNameQueryHandler
{
public function __construct(
private ProductRepository $productRepository
) {}
/**
* @return Product[]
*/
public function __invoke(ListProductsWithNameQuery $query): array
{
return $this->productRepository->getProductsWithName(
ProductName::fromString($query->name),
$query->itemPerPage,
$query->page
);
}
}
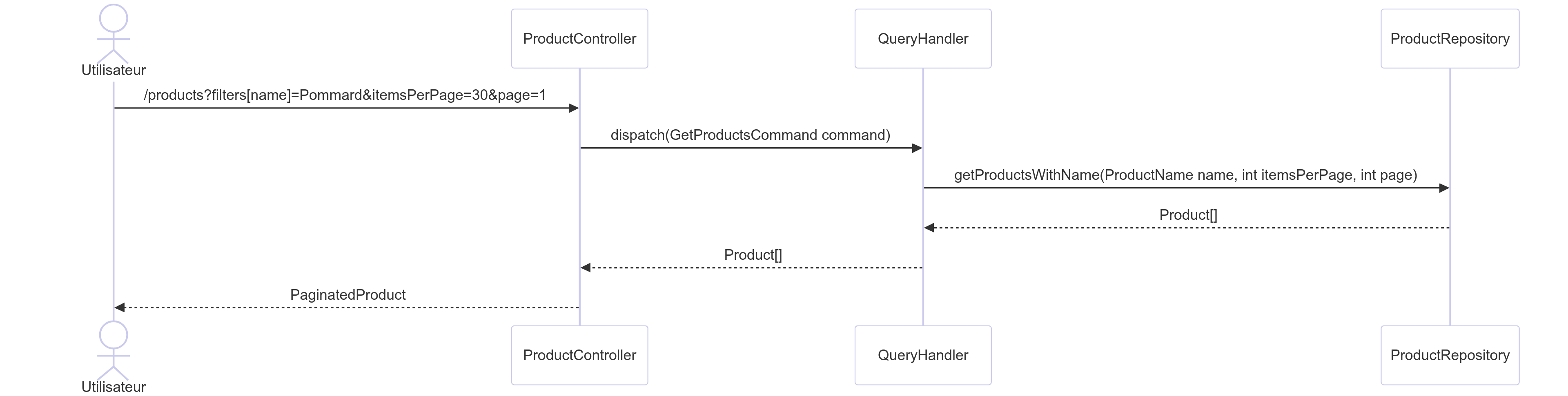
J’ai placé le Controller dans la couche Infrastructure. Il a pour but de transformer ce qui vient de la requête HTTP en Query pour ensuite la dispatcher.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
namespace App\Infrastructure\Controller;
final class ProductController extends AbstractController
{
public function __construct(
private readonly QueryBus $queryBus,
) {}
public function __invoke(Request $request): Response
{
$products = $this->queryBus->ask(
new ListProductsWithNameQuery(
$request->query->get('name'),
(int) $request->query->get('itemPerPage'),
(int) $request->query->get('page'),
)
);
$paginatedProduct = new PaginatedProduct(
products: $products,
total: count($products),
page: (int) $request->query->get('page'),
);
return $this->json($paginatedProduct);
}
}
Analyse de la mise en œuvre
Cet exemple d’implémentation d’une recherche de produit paginé respecte la séparation des couches de l’Architecture Hexagonale : le code métier est bien séparé de la couche Infrastructure. Il respecte aussi une partie du CQRS puisque je passe par une Query pour interroger le système.
En revanche, le modèle de lecture n’est pas séparé du modèle d’écriture, ce qui est un non-respect du CQRS. J’ai initialement pensé que ce n’était pas grave jusqu’à ce que cela induise une erreur : mon Domaine est pollué par des notions de la couche Infrastructure (ou de présentation). La pagination n’étant pas une partie du Domaine, elle ne lui apporte aucune valeur et peut changer en fonction de l’Adapter primaire (HTTP, Console…). Le filtre par nom, quant à lui, est un use case métier, mais il n’apporte pas grand-chose au Domaine et fait aussi partie de la couche de présentation.
Mais alors, comment gérer la pagination sans polluer mon Domaine ?
Ce n’est certainement pas la seule façon de faire, mais j’ai choisi de me conformer au CQRS complètement et de séparer le modèle d’écriture du modèle de lecture. J’ai donc déplacé le modèle de lecture dans la couche Infrastructure (ou la couche Application) ; il peut même être extrait du projet qui gère le Domaine des produits. Pour cela, à chaque action sur le modèle (création, modification ou suppression d’Aggregate ou d’Entity), je le répercute dans le modèle de lecture.
Avantages de cette approche
- Ce modèle de lecture est adapté à un besoin de présentation. Vous n’êtes donc pas contraints de sauvegarder les données de l’Aggregate ou de l’Entity si vous n’en avez pas besoin.
- Vous n’êtes pas obligés de respecter la structure de votre modèle d’écriture. Par exemple, si vous gérez une soirée avec des invitations et que vous devez filtrer ces invitations pour n’afficher que celles correspondant à un utilisateur spécifique, vous créez un modèle dédié aux invitations dans votre modèle de lecture et vous y incluez toutes les informations nécessaires (qu’elles proviennent de la soirée ou de l’invitation). La duplication des données n’a ici aucune importance.
- Pas de contrainte de stockage du modèle. Vous pouvez utiliser le même serveur pour mutualiser les coûts, je recommande juste de séparer les bases de données pour une séparation physique minimale. Vous pouvez également utiliser un stockage adapté comme Elasticsearch ou MongoDB. Cette problématique ne concernant pas l’Architecture du logiciel, je n’en parlerai pas plus dans cet article.
Mise en œuvre de cette solution
Je vais détailler ici les différentes étapes que j’ai mises en œuvre afin de séparer le modèle d’écriture et le modèle de lecture.
Transformation de modèle d’écriture en modèle de lecture
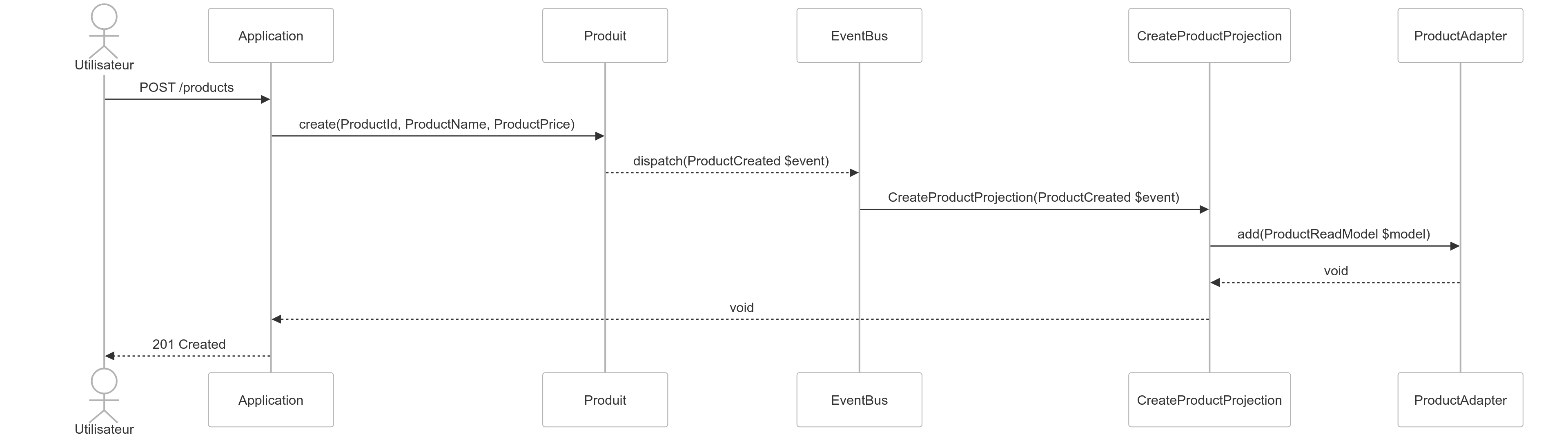
J’utilise pour cela les événements du Domaine et les Projections.
- Qu’est-ce qu’un événement du Domaine ? C’est un événement dispatché quand une action se produit dans le Domaine. Par exemple, lors de la création d’un produit, on dispatche un événement produit créé.
- Qu’est-ce qu’une Projection ? C’est le fait de projeter le modèle d’écriture dans le modèle de lecture. C’est une partie de la couche Infrastructure ou de la couche Application. Une Projection est appelée en réponse à l’événement émis par le Domaine.
Création du modèle de lecture
Je vais maintenant présenter la création du modèle de lecture et ensuite la partie lecture transformée pour utiliser le Read Model.
Voici l’Entity Product avec l’enregistrement de l’évènement lors de la création du Product :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
namespace App\Domain\Entity;
final class Product extends Aggregate
{
public function __construct(
private ProductId $id,
private ProductName $name,
private ProductPrice $price,
) {
}
public function create(
ProductId $id,
ProductName $name,
ProductPrice $price,
): self {
$product = new self(
$id,
$name,
$price,
);
$this->record(new ProductCreated(
$id->value(),
$name->value(),
$price->value(),
));
return $product;
}
public function id(): ProductId
{
return $this->id;
}
public function name(): ProductName
{
return $this->name;
}
public function price(): ProductPrice
{
return $this->price;
}
}
Voilà la Projection qui peut soit être appelée, soit être déjà présente dans un EventListener ou un MessageHandler. Pour le besoin d’un exemple court, j’ai mis le code directement dans l’EventListener. Je recommande de le sortir dans une classe dédiée.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
namespace App\Infrastructure\Projection;
final readonly class CreateProductProjection
{
public function __construct(
private ProductAdapterInterface $productAdapter,
) {
}
public function __invoke(ProductCreated $event): void
{
$product = new Product(
$event->productId,
$event->name,
$event->price,
);
$this->productAdapter->add($product);
}
}
Voilà l’Adapter qui sera en charge de stocker les données dans le modèle de lecture :
1
2
3
4
5
6
namespace App\Infrastructure\Adapter;
interface ProductAdapterInterface
{
public function add(Product $product): void;
}
L’implémentation dépendra de la solution que vous choisirez.
Voici à quoi ressemble le modèle de lecture du Product :
1
2
3
4
5
6
7
8
9
10
namespace App\Infrastructure\ReadModel;
final readonly class Product
{
public function __construct(
public string $id,
public string $name,
public float $price,
) {}
}
Le modèle de lecture est désormais prêt, il faut maintenant l’interroger.
Interrogation du modèle de lecture
Pour cela, j’ai repris le schéma du Use Case que j’ai un peu modifié :
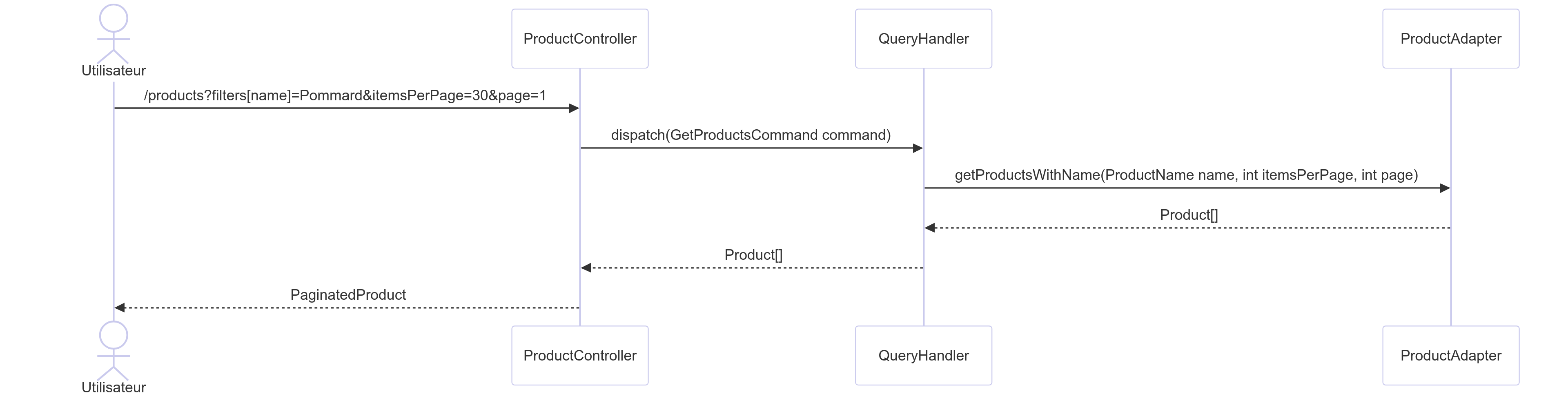
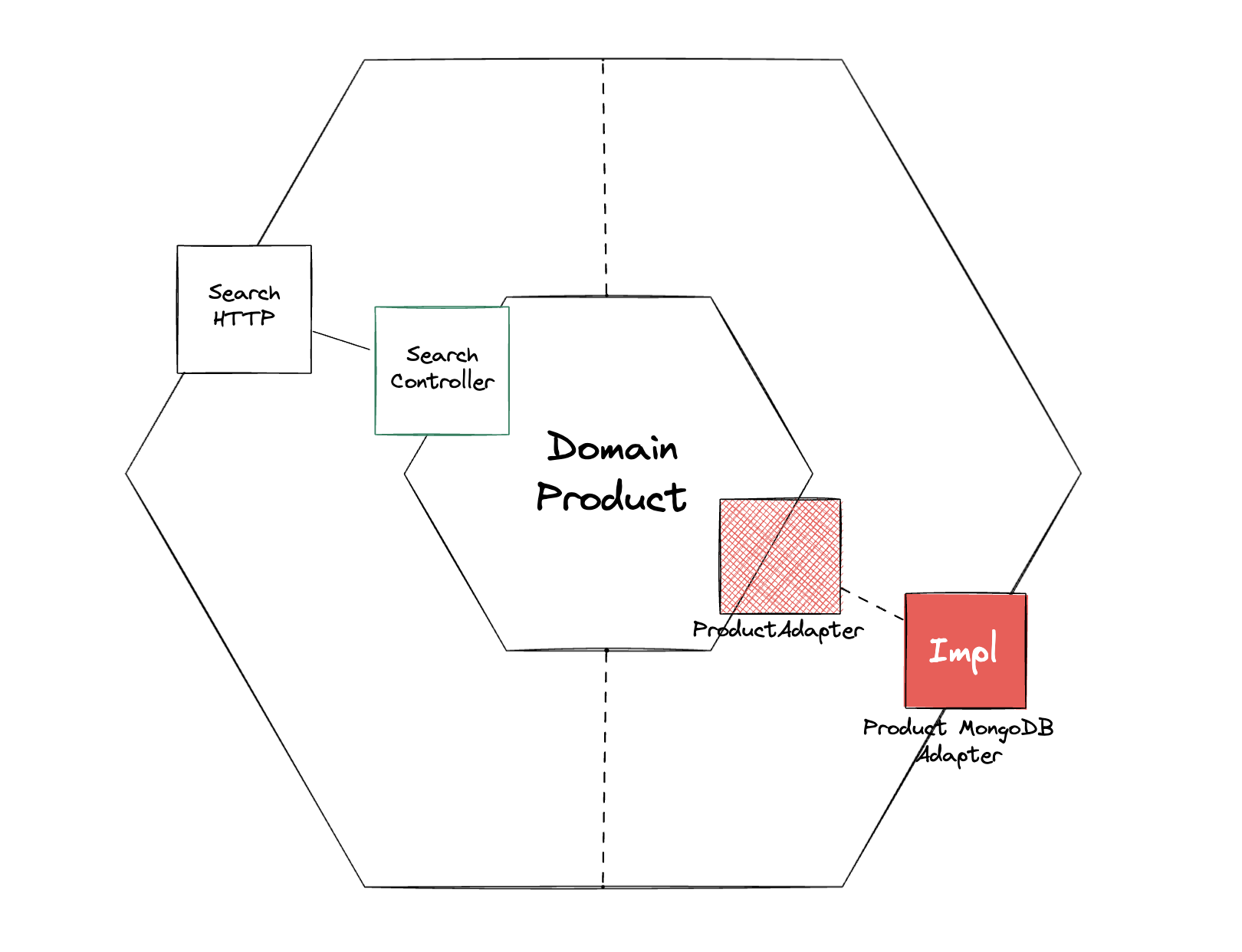
L’Adapter de lecture ne se trouve donc maintenant plus dans le Domaine, mais dans la couche Infrastructure.
1
2
3
4
5
6
7
8
9
10
11
namespace App\Infrastructure\Adapter;
interface ProductAdapterInterface
{
public function add(Product $product): void;
/**
* @return Product[]
*/
public function getProductsWithName(string $name, int $itemPerPage, int $page): array;
}
L’Adapter est donc en charge de lire le modèle de lecture, on y retrouve la méthode qui était dans le Repository de l’exemple précédent. J’ai modifié le paramètre name, pour que ce ne soit plus qu’une simple String. Puisqu’on est en dehors du Domaine, il n’est plus nécessaire que ce soit un Value Object.
La Query ne change pas :
1
2
3
4
5
6
7
8
9
10
11
namespace App\Infrastructure\Query;
final readonly class ListProductsWithNameQuery
{
public function __construct(
public string $name,
public int $itemPerPage,
public int $page,
) {
}
}
Dorénavant, le QueryHandler n’appellera plus le Repository du Domaine mais l’Adapter qui lit dans le Read Model :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
namespace App\Infrastructure\Query;
final readonly class ListProductsWithNameQueryHandler
{
public function __construct(
private ProductAdapterInterface $productAdapter
) {}
/**
* @return Product[]
*/
public function __invoke(ListProductsWithNameQuery $query): array
{
return $this->productAdapter->getProductsWithName(
$query->name,
$query->itemPerPage,
$query->page
);
}
}
Le Controller ne change pas non plus :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
namespace App\Infrastructure\Controller;
final class ProductController extends AbstractController
{
public function __construct(
private readonly QueryBus $queryBus,
) {}
public function __invoke(Request $request): Response
{
$products = $this->queryBus->ask(
new ListProductsWithNameQuery(
$request->query->get('name'),
(int) $request->query->get('itemPerPage'),
(int) $request->query->get('page'),
)
);
$paginatedProduct = new PaginatedProduct(
products: $products,
total: count($products),
page: (int) $request->query->get('page'),
);
return $this->json($paginatedProduct);
}
}
J’ai tenté de répondre à la question : la pagination est-elle un besoin métier ou un besoin technique ? De ce qu’on a vu, la pagination fait partie des use cases métier mais ne relève pas de la responsabilité du Domaine. Il est donc nécessaire de l’intégrer en dissociant le modèle de lecture du modèle du Domaine. Une telle approche permet de garder l’intégrité du Domaine en le maintenant à l’écart des problématiques qui ne relèvent pas de son périmètre.
Pour les intéressés, vous pouvez retrouver tout le code de cet article sur GitHub. Vous y trouverez le code sans le Read Model ainsi que la dernière version.
Je vous donne rendez-vous dans quinze jours pour un prochain article du Journal de Bord du DDD.